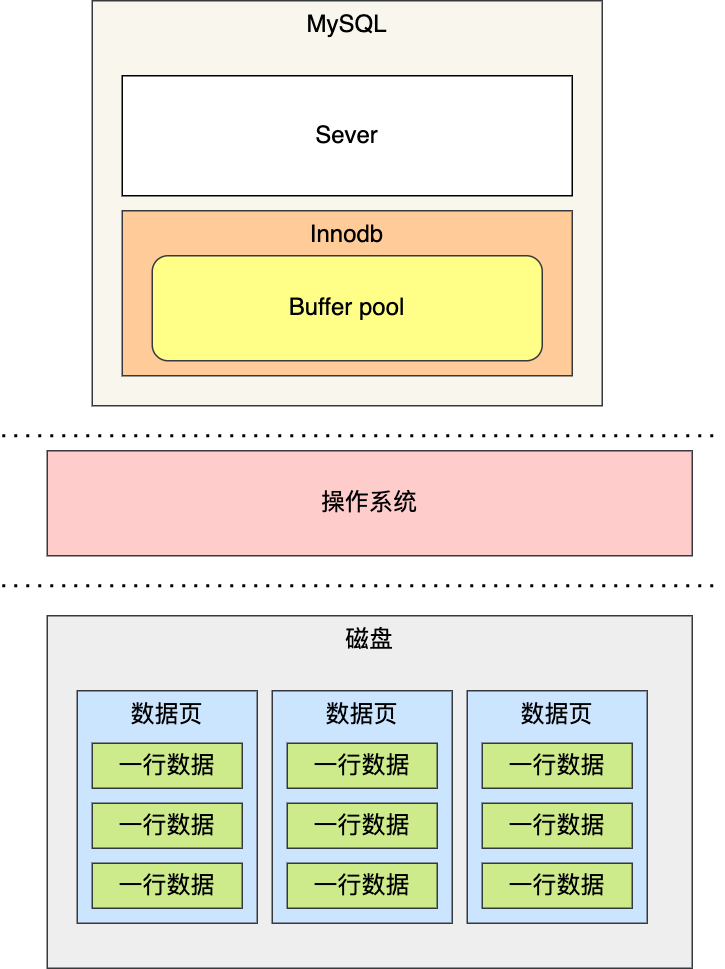
存储引擎
- 查看表的存储引擎
1
2
3
4
5
6
7
8
9
10
11
12
13
| mysql> show create table bills;
+
| Table | Create Table |
+
| bills | CREATE TABLE `bills` (
`id` int NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`money` double DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci |
+
1 row in set (0.00 sec)
|
- 查看数据库支持的存储引擎
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| mysql> show engines;
+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+
| MEMORY | YES | 存储在内存一般用于临时表 | NO | NO | NO |
| MRG_MYISAM | YES | 允许多表合并 | NO | NO | NO |
| CSV | YES | 文件存储引擎可以导出数据 | NO | NO | NO |
| FEDERATED | NO | 远程表存储引擎 | NULL | NULL | NULL |
| PERFORMANCE_SCHEMA | YES | 管理和监控MySQL服务器性能的工具| NO | NO | NO |
| MyISAM | YES | 读取性能高 全文索引 表级锁 | NO | NO | NO |
| InnoDB | DEFAULT | 默认引擎 行级锁 | YES | YES | YES |
| BLACKHOLE | YES | 不存储真实数据,主要进行数据流的传输和路由 | NO | NO |NO |
| ARCHIVE | YES | 基于行的存储引擎 | NO | NO | NO |
+
9 rows in set (0.00 sec)
|
- 存储结构

- 常用存储引擎的区别
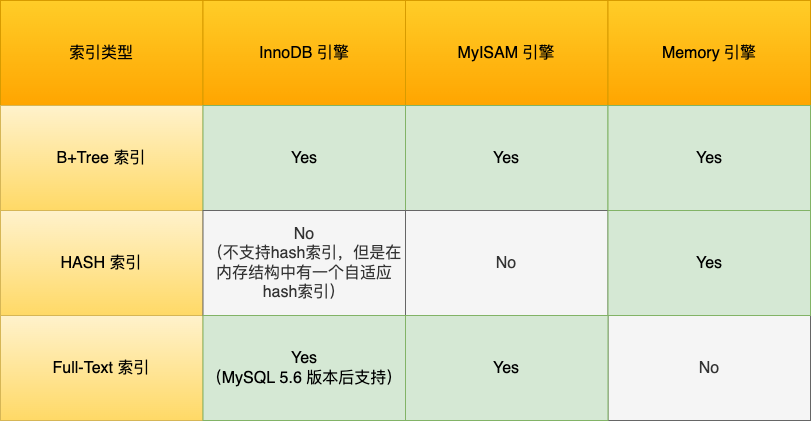
索引
按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
按「字段个数」分类:单列索引、联合索引。
| 优势 |
劣势 |
| 提高搜索效率 降低IO成本吗 |
索引列占用额外空间 |
| 降低排序成本,降低CPU消耗 |
提高了查找效率,但是降低的修改效率 |
桉数据结构分类
Innodb存储引擎会根据不同的场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键(key);
- 如果没有主键,就选择第一个不包含 NULL 值的唯一(UNIQUE)列作为聚簇索引的索引键(key);
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键(key);
按物理存储分类
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
1
2
3
4
5
| - 分析查表步骤 假设id为主键
①select * from user where id = 10;
②select * from user where name = 'john';
- 第一个查询走主键索引直接查询到数据
- 第二个查询走二级索引先查询到对应主键值再回表根据主键索引查询数据
|
按字段特性分类
语法
1
2
| CREATE UNIQUE INDEX indexName ON table (col_Name,。。。);
CREATE FULLETEXT INDEX indexName ON table (col_Name,。。。);
|
1
| SHOW INDEX FROM table_name;
|
1
| DROP INDEX index_name on table_name;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
mysql> select * from user;
+
| id | username | emila | password |
+
| 1 | Gin | Gin@163.com | 123456 |
| 2 | zerotwo | zerotwo@163.com | 123456 |
| 3 | panther | Gin@163.com | 123456 |
+
3 rows in set (0.00 sec)
mysql> show index from user;
+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+
| user | 0 | PRIMARY | 1 | id | A | 2 | NULL | NULL | | BTREE | | | YES | NULL |
+
2 rows in set (0.00 sec)
create index idx_user_name on user(username);
create unique index idx_user_em on user(emila);
create index idx_user_name_em on user(name , emila);
drop index idx_user_name on user;
|
性能分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
|
mysql> show global status like 'com_______';
+
| Variable_name | Value |
+
| Com_binlog | 0 |
| Com_commit | 0 |
| Com_delete | 0 |
| Com_import | 0 |
| Com_insert | 0 |
| Com_repair | 0 |
| Com_revoke | 0 |
| Com_select | 21 |
| Com_signal | 0 |
| Com_update | 0 |
| Com_xa_end | 0 |
+
11 rows in set (0.01 sec)
mysql> show variables like 'slow_query_log';
+
| Variable_name | Value |
+
| slow_query_log | ON |
+
1 row in set, 1 warning (0.00 sec)
slow_query_log = 1
long_query_time = 2
slow_query_log_file = /var/log/mysql/slow.log
Time Id Command Argument
# Time: 2023-05-23T15:45:39.6886792
# User @ Host:root [root]localhost [Id:8
# Query time: 13.350650
# Lock time: 0.000358 Rows sent:1Rows examined:0
use test;
SET timestamp=1635435926;
select count(*)from tb_sku;
mysql> select @@have_profiling;
+
| @@have_profiling |
+
| YES |
+
1 row in set, 1 warning (0.00 sec)
mysql> select @@profiling;
+
| @@profiling |
+
| 0 |
+
1 row in set, 1 warning (0.00 sec)
mysql> set profiling = 1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show profiles;
+
| Query_ID | Duration | Query |
+
| 1 | 0.00032050 | SELECT DATABASE() |
| 2 | 0.01238825 | select * from user |
| 3 | 0.00036200 | select * from user where id = 2 |
| 4 | 0.00098675 | select * from user where username like '%two' |
| 5 | 0.00023250 | select count(*) |
+
5 rows in set, 1 warning (0.00 sec)
mysql> show profile for query 3;
+
| Status | Duration |
+
| starting | 0.000093 |
| Executing hook on transaction | 0.000003 |
| starting | 0.000006 |
| checking permissions | 0.000004 |
| Opening tables | 0.000054 |
| init | 0.000003 |
| System lock | 0.000006 |
| optimizing | 0.000027 |
| statistics | 0.000064 |
| preparing | 0.000010 |
| executing | 0.000009 |
| end | 0.000002 |
| query end | 0.000002 |
| waiting for handler commit | 0.000009 |
| closing tables | 0.000006 |
| freeing items | 0.000056 |
| cleaning up | 0.000010 |
+
17 rows in set, 1 warning (0.00 sec)
mysql> explain select * from user where username like '%two';
+
| id | select_type | table | partitions | type |
| 1 | SIMPLE | user | NULL | ALL |
+
mysql> explain select * from user where id = 3 or username = 'Gin';
+
| id | select_type | table | partitions | type |
+
| 1 | SIMPLE | user | NULL | ALL |
+
mysql> explain select * from user where length(username)=3;
+
| id | select_type | table | partitions | type |
+
| 1 | SIMPLE | user | NULL | ALL |
+
mysql> explain select * from user where id + 1 = 2;
+
| id | select_type | table | partitions | type |
+
| 1 | SIMPLE | user | NULL | ALL |
+
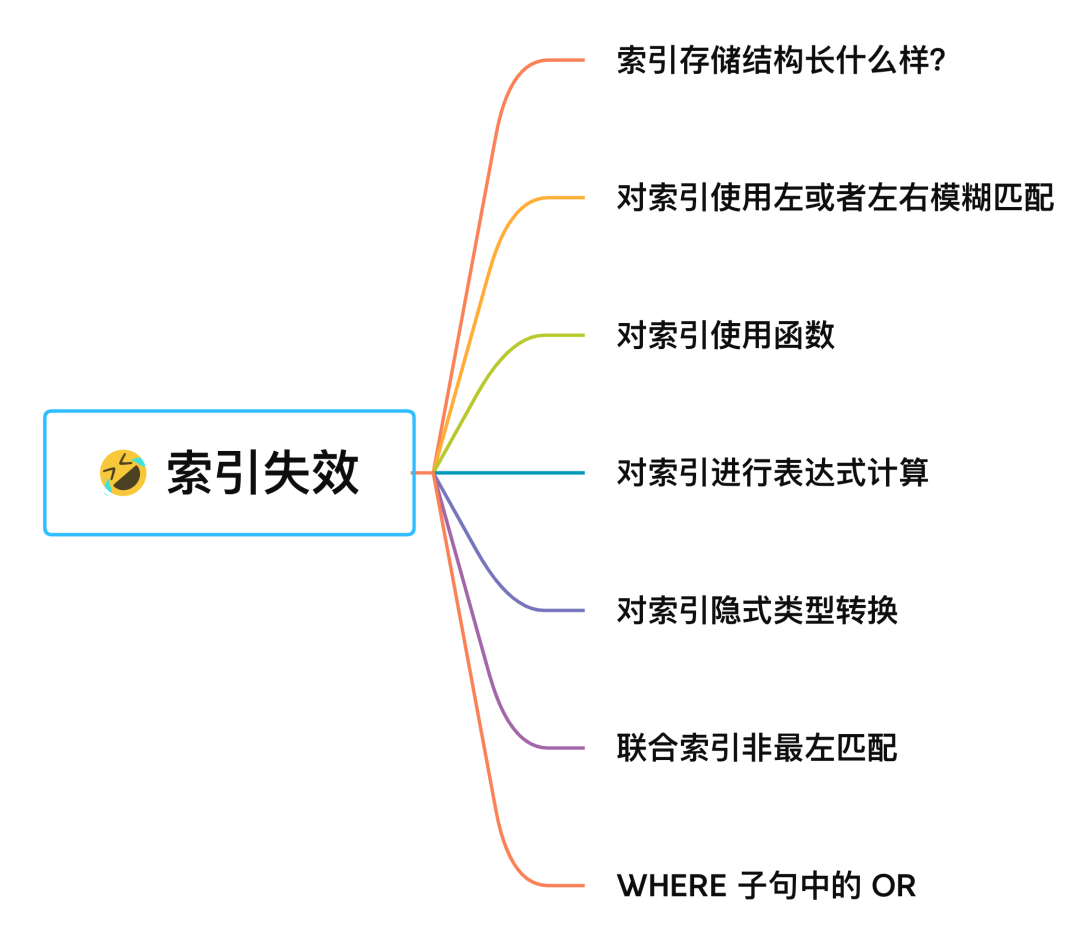
- ① 模糊匹配中有左% 索引失效 进行了全表扫描
- ② 使用 or 关键字时 如果 两边有一边没有索引则索引失效
- ③ 对索引使用函数 因为索引保存的是索引字段的原始值,而不是经过函数计算后的值
- ④ 对索引进行表达式计算
|
覆盖索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
mysql> create index idx_user_username on user(username);
mysql> create index idx_user_email on user(email);
mysql> explain select id,username,email from user where username='panther' and emila = 'Gin@163.com';
+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+
| 1 | SIMPLE | user | NULL | ref | idx_user_username,idx_user_email | idx_user_username | 83 | const | 1 | 100.00 | NULL |
+
1 row in set, 1 warning (0.00 sec)
mysql> create index idx_username_email on user(username,email);
mysql> explain select id,username,emila from user where username='panther' and emila = 'Gin@163.com';
+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+
| 1 | SIMPLE | user | NULL | ref | idx_user_username,idx_user_email,idx_username_email | idx_username_email | 286 | const,const | 1 | 100.00 | Using index |
+
|
count(*) 和count(1)的区别 ,哪个性能好?
COUNT()统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个。
count(主键字段)如果表里只有主键索引,没有二级索引时,那么,InnoDB 循环遍历聚簇索引,将读取到的记录返回给 server 层,然后读取记录中的 id 值
count(1)InnoDB 循环遍历聚簇索引(主键索引),将读取到的记录返回给 server 层,但是不会读取记录中的任何字段的值
count(*) 执行过程跟 count(1) 执行过程基本一样的
count(字段) 对于这个查询来说,会采用全表扫描的方式来计数,所以它的执行效率是比较差的。
SQL优化
① 大批量的插入
② order by 、limit、count、update等常见关键字优化
大批量插入数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
PS C:\Users\admin> mysql
mysql> select @@local_infile;
+
| @@local_infile |
+
| 0 |
+
1 row in set (0.00 sec)
mysql> set global local_infile = 1;
Query OK, 0 rows affected (0.00 sec)
4, john1,jogn1@163.com,123456
5, john2,jogn2@163.com,123456
6, john3,jogn3@163.com,123456
。。。。。
mysql> load data local infile 'D:\loadTest.sql' into table user fields terminated by ',' lines terminated by '\n';
|
主键优化
顺序插入比乱序插入性能更高(因为sql的数据结构为B+Tree是有序的当乱序插入数据,需要多出调整树结构的复杂度)
order by 优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
mysql> explain select * from user order by username;
+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using filesort |
+
1 row in set, 1 warning (0.00 sec)
mysql> create index idx_user_name on user(username);
mysql> explain select * from user order by username asc;
+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using index |
+
mysql> create index idx_user_name on user(username desc);
mysql> create index idx_user_name on user(username desc ,age asc);
|
limit 优化
1
2
3
4
5
|
select * from user limit 1000000,10;
select id from user limit 1000000,10;
select id,name from user limit 1000000,10;
|
count 优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
mysql> explain select count(*) from employees;
+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+
| 1 | SIMPLE | employees | NULL | index | NULL | dept_id_fk | 5 | NULL | 107 | 100.00 | Using index |
+
1 row in set, 1 warning (0.00 sec)
mysql> explain select count(1) from employees;
+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+
| 1 | SIMPLE | employees | NULL | index | NULL | dept_id_fk | 5 | NULL | 107 | 100.00 | Using index |
+
1 row in set, 1 warning (0.00 sec)
mysql> explain select count(employee_id) from employees;
+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+
| 1 | SIMPLE | employees | NULL | index | NULL | dept_id_fk | 5 | NULL | 107 | 100.00 | Using index |
+
1 row in set, 1 warning (0.00 sec)
mysql> explain select count(last_name) from employees;
+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 107 | 100.00 | NULL |
+
1 row in set, 1 warning (0.00 sec)
|
update 优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update user set password = '123456' where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update user set password = '123666' where name = 'panther';
|
1
2
3
4
5
6
7
8
9
10
11
12
|
mysql> update user set password = '666666' where id = 3;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
mysql> update user set password = '666666' where id = 1;
光标停在这里
Query OK, 1 row affected (33.62 sec)
Rows matched: 1 Changed: 1 Warnings: 0
|
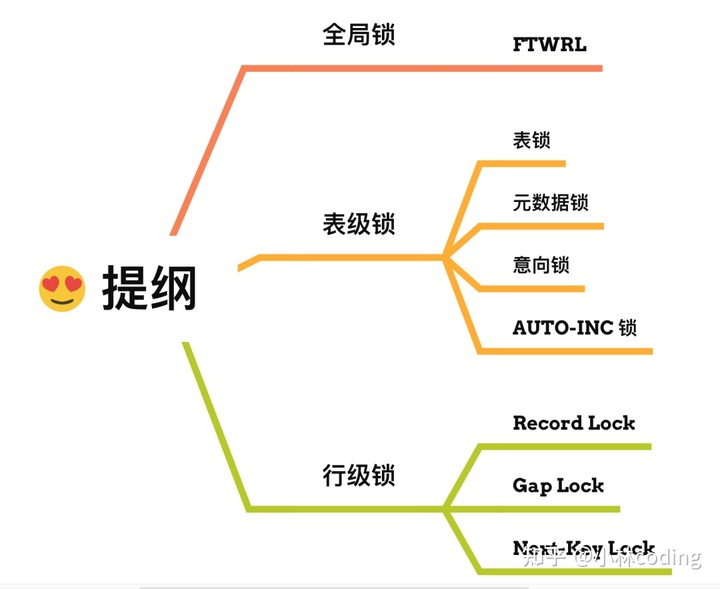
锁
全局锁
1
| flush tables with read lock;
|
执行后,整个数据库就处于只读状态了,这时其他线程执行以下操作,都会被阻塞:
- 对数据的增删改操作,比如 insert、delete、update等语句;
- 对表结构的更改操作,比如 alter table、drop table 等语句。
如果要释放全局锁,则要执行这条命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
mysql> flush tables with read lock;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user;
+
| id | username | emila | password |
+
| 1 | Gin | Gin@163.com | 666666 |
| 2 | zerotwo | zerotwo@163.com | 123456 |
| 3 | panther | Gin@163.com | 666666 |
+
3 rows in set (0.00 sec)
mysql> update user set password = '123456' where id = 1;
ERROR 1223 (HY000): Can't execute the query because you have a conflicting read lock
-- 备份 mysqldump不是mysql的语法 而是mysql提供的工具 所以在CMD中运行即可
PS C:\Users\admin> mysqldump -uroot -pxxxx test > D:\test.sql
mysqldump: [Warning] Using a password on the command line interface can be insecure.
-- 释放锁
mysql> unlock tables;
Query OK, 0 rows affected (0.00 sec)
|
表锁
1
2
3
4
5
6
7
8
9
|
lock tables 表名 read;
lock tables 表名 write;
unlock tables
|
我们不需要显示的使用 MDL(元数据锁),因为当我们对数据库表进行操作时,会自动给这个表加上 MDL:
- 对一张表进行 CRUD 操作时,加的是 MDL 读锁;
- 对一张表做结构变更操作的时候,加的是 MDL 写锁;
MDL 是为了保证当用户对表执行 CRUD 操作时,防止其他线程对这个表结构做了变更。
MDL 是在事务提交后才会释放,这意味着事务执行期间,MDL 是一直持有的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
mysql> select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
+
| object_type | object_schema | object_name | lock_type | lock_duration |
+
| TABLE | performance_schema | metadata_locks | SHARED_READ | TRANSACTION |
+
1 row in set (0.00 sec)
mysql> begin;
mysql> select * from user;
mysql> select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
+
| object_type | object_schema | object_name | lock_type | lock_duration |
+
| TABLE | test | user | SHARED_READ | TRANSACTION |
| TABLE | performance_schema | metadata_locks | SHARED_READ | TRANSACTION |
+
2 rows in set (0.00 sec)
mysql> update user set password = '123666' where id = 1;
mysql> select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
+
| object_type | object_schema | object_name | lock_type | lock_duration |
+
| TABLE | test | user | SHARED_WRITE | TRANSACTION |
| TABLE | performance_schema | metadata_locks | SHARED_READ | TRANSACTION |
+
2 rows in set (0.00 sec)
mysql> alter table user add column age int;
|
- 在使用 InnoDB 引擎的表里对某些记录加上「共享锁」之前,需要先在表级别加上一个「意向共享锁」;
- 在使用 InnoDB 引擎的表里对某些纪录加上「独占锁」之前,需要先在表级别加上一个「意向独占锁」;
也就是,当执行插入、更新、删除操作,需要先对表加上意向独占锁,然后对该记录加独占锁。
意向共享锁和意向独占锁是表级锁,不会和行级的共享锁和独占锁发生冲突,而且意向锁之间也不会发生冲突,只会和共享表锁(*lock tables … read*)和独占表锁(*lock tables … write*)发生冲突。
行锁
行级锁的类型主要有三类:
- Record Lock,记录锁,也就是仅仅把一条记录锁上;
- Gap Lock,间隙锁,锁定一个范围,但是不包含记录本身;
- Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
如果在检索数据时没有通过索引,进行了全表扫描,则行锁会升级成表锁
Record Lock 记录锁(在隔离级别在READ COMMITED 和REPEATABLE READ 时生效)
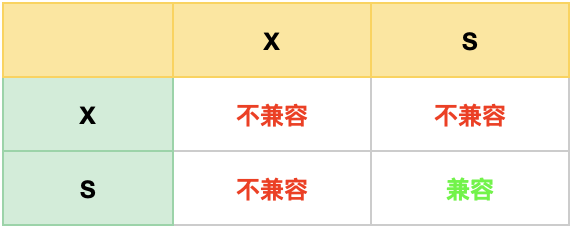
Record Lock 称为记录锁,锁住的是一条记录。而且记录锁是有 S(共享锁) 锁和 X(排他锁) 锁之分的:
- 当一个事务对一条记录加了 S 型记录锁后,其他事务也可以继续对该记录加 S 型记录锁(S 型与 S 锁兼容),但是不可以对该记录加 X 型记录锁(S 型与 X 锁不兼容);
- 当一个事务对一条记录加了 X 型记录锁后,其他事务既不可以对该记录加 S 型记录锁(S 型与 X 锁不兼容),也不可以对该记录加 X 型记录锁(X 型与 X 锁不兼容)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
mysql> begin;
mysql> select * from user where id = 1 lock in share mode;
mysql> select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
+
| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |
+
| test | user | NULL | TABLE | IS | NULL |
| test | user | PRIMARY | RECORD | S,REC_NOT_GAP | 1 |
+
2 rows in set (0.00 sec)
mysql> select * from user where id = 1 lock in share mode;
+
| id | username | emila | password |
+
| 1 | Gin | Gin@163.com | 123456 |
+
1 row in set (0.00 sec)
mysql> update user set password = '123456' where id = 1;
mysql> begin;
mysql> select * from user where id = 1 for update;
mysql> select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
+
| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |
+
| test | user | NULL | TABLE | IX | NULL |
| test | user | PRIMARY | RECORD | X,REC_NOT_GAP | 1 |
+
2 rows in set (0.00 sec)
mysql> select * from user where id = 1 lock in share mode;
mysql> update user set password = '123456' where id = 1;
|
Gap lock 间隙锁(只存在于可重复读隔离级别)
目的是为了解决可重复读隔离级别下幻读的现象。
假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生。
间隙锁虽然存在 X 型间隙锁和 S 型间隙锁,但是并没有什么区别,间隙锁之间是兼容的,即两个事务可以同时持有包含共同间隙范围的间隙锁,并不存在互斥关系,因为间隙锁的目的是防止插入幻影记录而提出的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
+
| id | username | email | password |
+
| 3 | panther | Gin@163.com | 666666 |
| 13 | john | john@163.com | 123456 |
+
4 rows in set (0.00 sec)
mysql> update user set password = '123456' where id = 12;
Query OK, 0 rows affected (0.00 sec)
mysql> select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
+
| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |
+
| test | user | NULL | TABLE | IX | NULL |
| test | user | PRIMARY | RECORD | X,GAP | 13 |
+
2 rows in set (0.00 sec)
mysql> insert into user values(12 , 'john' ,'john@163.com','123456')
|
Next-Key Lock 临键锁(只存在于可重复读隔离级别)
是 Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
表中有一个范围 id 为(3,5] 的 next-key lock,那么其他事务即不能插入 id = 4 记录,也不能修改 id = 5 这条记录。
如果一个事务获取了 X 型的 next-key lock,那么另外一个事务在获取相同范围的 X 型的 next-key lock 时,是会被阻塞的
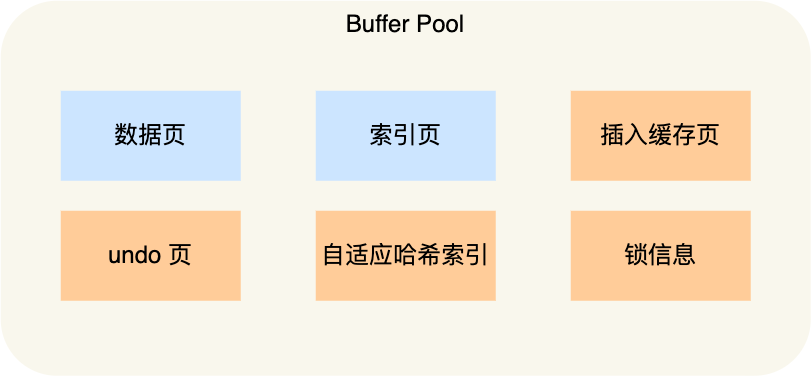
Buffe pool
Innodb 存储引擎设计了一个缓冲池(Buffer Pool),来提高数据库的读写性能
- 当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。
- 当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页写入到磁盘。
buffer pool 缓存的东西
1
2
3
4
5
6
7
| mysql> show variables like 'innodb_buffer_pool_size';
+
| Variable_name | Value |
+
| innodb_buffer_pool_size | 8388608 |
+
1 row in set, 1 warning (0.00 sec)
|
MVCC
当前读
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
mysql> begin;
mysql> select * from user;
+
| id | username | email | password |
+
| 1 | Gin | Gin@163.com | 123456 |
| 13 | john | john@163.com | 123456 |
+
2 rows in set (0.00 sec)
mysql> begin;
mysql> update user set username = 'john2' where id = 13;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
mysql> select * from user;
+
| id | username | email | password |
+
| 1 | Gin | Gin@163.com | 123456 |
| 13 | john | john@163.com | 123456 |
+
2 rows in set (0.00 sec)
mysql> select * from user lock in share mode;
+
| id | username | email | password |
+
| 1 | Gin | Gin@163.com | 123456 |
| 13 | john2 | Gin@163.com | 666666 |
+
|
表中的三个隐藏字段
undo log日志(回滚日志)和 ReadView
对于「读提交」和「可重复读」隔离级别的事务来说,它们的快照读(普通 select 语句)是通过 Read View + undo log 来实现的,它们的区别在于创建 Read View 的时机不同:
- 「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
- 「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。
三大日志(binlog、redo log和undo log)
① redo log(重做日志)
② binlog(归档日志)
③ undo log(回滚日志)
redo log
redo log(重做日志)是InnoDB存储引擎独有的,它让MySQL拥有了崩溃恢复能力。
InnoDB 存储引擎为 redo log 的刷盘策略(将buffer pool的数据写入磁盘中)提供了 innodb_flush_log_at_trx_commit 参数,它支持三种策略:
- 0:设置为 0 的时候,表示每次事务提交时不进行刷盘操作
- 1:设置为 1 的时候,表示每次事务提交时都将进行刷盘操作
- 2:设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache
1
2
3
4
5
6
7
8
|
mysql> show variables like 'innodb_flush_log_at_trx_commit';
+
| Variable_name | Value |
+
| innodb_flush_log_at_trx_commit | 1 |
+
1 row in set, 1 warning (0.00 sec)
|
binlog
Binlog(Binary Log)日志是MySQL Server层生成的一种记录,包含了数据库执行的所有操作,无论是SQL语句的执行还是数据库数据的变更。这个重要的日志类型记录了数据库实例的所有DML(数据操作语言)和DDL(数据定义语言)操作。
Binlog对于MySQL数据库系统至关重要。每当执行增、删、改操作(即DML操作)时,这些操作都会被记录在Binlog日志文件中。同时,对数据库结构进行更改的DDL操作也会在Binlog中留下记录。
Binlog的重要性不仅在于它存储了所有对数据库的更改,还在于当数据库发生故障时,它有助于数据的恢复。通过阅读Binlog日志中的数据变更内容,我们能够重新执行这些操作,从而实现对数据的恢复。
binlog 日志有三种格式,可以通过binlog_format参数指定。
优点:不需要记录每一条SQL语句和每一行的数据变化,减少了binlog日志量,有助于提高性能
缺点:某些情况可能导致主从之间的数据不一致,例如在SQL语句中使用sleep()或last_insert_id()等操作
优点:任何情况下都可以复制,并且不会受到存储过程、函数等调用或触发器无法正确复制的问题的影响
缺点:binlog日志文件可能会变得非常大。相较于STATEMENT模式,可能导致更频繁的binlog并发写问题
是STATEMENT和ROW两种模式的混合使用
这种混合模式充分利用了两者的优势,同时避免了各自的缺点。
binlog 用于备份恢复、主从复制
MySQL 集群的主从复制过程梳理成 3 个阶段:
- 写入 Binlog:主库写 binlog 日志,提交事务,并更新本地存储数据。
- 同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
- 回放 Binlog:回放 binlog,并更新存储引擎中的数据。
Binlog的写入时机
- 在事务执行期间,日志首先被写入到每个线程的 binlog cache 中。
- 在事务提交时,binlog cache 的内容会一次性写入到 binlog 文件中。
undo log
undo log 是一种用于撤销回退的日志。在事务没提交之前,MySQL 会先记录更新前的数据到 undo log 日志文件里面,当事务回滚时,可以利用 undo log 来进行回滚。
每当 InnoDB 引擎对一条记录进行操作(修改、删除、新增)时,要把回滚时需要的信息都记录到 undo log 里,比如:
- 在插入一条记录时,要把这条记录的主键值记下来,这样之后回滚时只需要把这个主键值对应的记录删掉就好了;
- 在删除一条记录时,要把这条记录中的内容都记下来,这样之后回滚时再把由这些内容组成的记录插入到表中就好了;
- 在更新一条记录时,要把被更新的列的旧值记下来,这样之后回滚时再把这些列更新为旧值就好了。